Research Highlights
Why is the training of artificial neural networks so effective?
Our research reveals interesting characteristics of common learning techniques employed for training deep artificial neural networks that explain why the deep learning methodology is so effective. The aim of any learning technique is to reduce the "error" between the model prediction and the provided data in order to produce a model that best "fits" the data. This process involves adjusting thousands or even millions of parameters in the neural network, and improved parameters are obtained by "following" the decrease of the error between prediction and data. This work aims to understand what changes of the error function a typical optimiser observes during the training process of a deep artificial neural network.
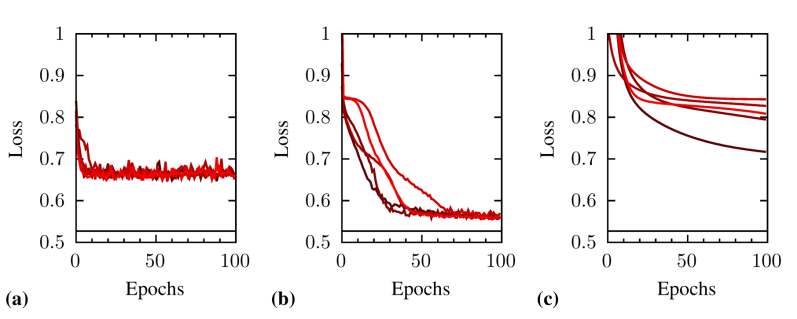
While deep learning is a conceptually simple, yet highly-effective, and widely-used tool, we still have insufficient understanding of how exactly it works. In particular, the training of deep artificial neural networks using standard algorithms such as "stochastic gradient descent" work unexpectedly well given the vast size of the optimisation space. Our work analyses the loss function (sometimes also referred to as the cost or error function) of deep neural networks and provides us with a better understanding of how commonly used training procedures can navigate the high-dimensional space of tunable parameters and find neural network models that perform well.
PC Verpoort, AA Lee and DJ Wales, "Archetypal landscapes for deep neural networks." Proc. National Academy of Sci. USA, 17 21857 (2020)