The argument for performing DMC calculations on a parallel computer is even more compelling than for VMC calculations, because DMC calculations require approximately an order of magnitude more CPU time than the equivalent VMC calculation.
As with VMC calculations, the DMC algorithm is intrinsically parallel.
In the algorithm outlined in section ![]() , an ensemble of
walkers is used to evaluate the local energy of the guiding function,
, an ensemble of
walkers is used to evaluate the local energy of the guiding function,
![]() , at each time step of the simulation. In our parallel
version of the DMC algorithm, this ensemble of walkers is distributed
across all NNODES nodes of the parallel machine. Each node is responsible
for performing stages (2)-(8) of the algorithm (the diffusion, drift
and creation/annihilation of walkers) on its own subset of the total
ensemble of walkers.
, at each time step of the simulation. In our parallel
version of the DMC algorithm, this ensemble of walkers is distributed
across all NNODES nodes of the parallel machine. Each node is responsible
for performing stages (2)-(8) of the algorithm (the diffusion, drift
and creation/annihilation of walkers) on its own subset of the total
ensemble of walkers.
After all the walkers have been advanced for a block of time steps, the mean energy across all the walkers on all the nodes is used to update the trial energy as in stage (11) of the algorithm.
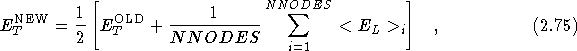
where ![]() is the accumulated local energy of the subset of
walkers on the i
is the accumulated local energy of the subset of
walkers on the i ![]() node.
node.
The renormalisation of the number of walkers at the end of a block is performed across all the nodes in the following way.
It is important to try and keep the number of walkers on each node equal, i.e. to `load balance' the algorithm efficiently. The efficiency of the algorithm at any one time step is determined by
![]()
where ![]() is the total number of walkers
across all the nodes and
is the total number of walkers
across all the nodes and ![]() is the number of
walkers on the node which at that particular time step has the largest
number of `live' walkers. The efficiency of the algorithm can
therefore be improved in two ways,
is the number of
walkers on the node which at that particular time step has the largest
number of `live' walkers. The efficiency of the algorithm can
therefore be improved in two ways,
![]()
In other words any one node can never have more than one more walker than any other node. For the DMC calculations reported on in this thesis, there are typically 10 walkers per node, yielding an average efficiency of approximately 95%.
The parallel DMC algorithm requires a set of equilibrated configurations as an input, in the same way as the serial DMC algorithm. These configurations are produced by instructing each node in the parallel VMC algorithm to write out an equilibrated ensemble of configurations.